 扫一扫 加微信
扫一扫 加微信大数据被认为是生产力的“第四次产业革命”和科学研究的“第四范式”,也是当前社会科学的前沿议题。尤其是美国学者麦克舍恩的专著《大数据时代:生活、工作和思维的大变革》(BigData: A Revolution That Will Transform How We Live, Work, and Think)于2013年在中国翻译出版以来,“大数据”迅速成为一个“热门”概念,各行各业几乎“言必称大数据”,社会治理也是如此。
必须承认,大数据驱动的社会治理应该成为中国社会治理创新的重要方向,需要予以重视,加大投入力度,提高推进速度。在国家层面,建设全国一体化的国家大数据中心已经提上议事日程;[1]在社会治理领域,运用大数据提升社会治理的智能化水平也已经成为大势所趋。[2]
然而,仅仅停留于“大数据”的概念并不能解决中国社会治理的诸多难题,大数据驱动是技术、产业、战略和思维四大要素的系统驱动,任何一个要素的缺失都可能影响到大数据驱动社会治理的实效。与此同时,大数据驱动在本质上是信息驱动,[3]信息技术手段的使用虽然可以解决中国社会治理的很多问题,但并非全部问题,因此需要澄清大数据驱动社会治理的社会机制和问题领域。此外,大数据驱动社会治理作为一项社会创新,除技术条件外,不可避免地还要受到文化、制度、结构等社会因素的制约,只有正视并消除这些因素的制约,才能使大数据驱动的社会治理真正“落地生根”。
基于上述三个目的,本文对大数据驱动的社会治理的讨论主要聚焦于三个问题:第一,大数据驱动社会治理的系统要素;第二,大数据驱动社会治理的学理逻辑;第三,大数据驱动社会治理的制约因素。
一、大数据驱动社会治理的系统要素
在“大数据”概念出现之前,就已经存在着大数据的事实了。从这种意义上来看,“大数据”的兴起至少可以追溯至软件行业的开源运动。2004年,美国普林斯顿大学本科生乔舒亚·陶博拉(Joshua Tauberer)建立了世界首个公共数据开放的网站。2007年,公共数据开放的倡导者们共同确立了数据开放的8项原则:(1)数据必须是完整的;(2)数据必须是原始的;(3)数据必须是及时的;(4)数据必须是可读取的;(5)数据必须是机器可以处理的;(6)数据的获取必须是无歧视的;(7)数据的格式必须是通用的而非专有的;(8)数据必须是不需要许可证的。[4]
“大数据”概念的兴起是一个动态扩散的过程,从最初在软件行业的实际应用,到现在对社会生活乃至思维方式的影响,经历了五个阶段,见图1所示。
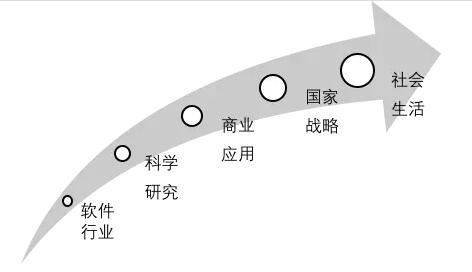
图1“大数据”概念的扩散
这同时也意味着,“大数据”是个多维概念,在不同的语境下,人们虽然都共同言称“大数据”,但可能各有所指。因此,有必要厘清“大数据”概念的维度,完整地定义大数据。从上述扩散过程来看,“大数据”概念至少可以有四个维度:第一,技术维度,指大数据技术;第二,经济维度,指大数据产业;第三,政治维度,指大数据战略;第四,社会维度,指大数据思维。
首先来看技术维度。大概而论,大数据技术是指收集、发现和分析多种类型的大规模数据,并从中提取价值的技术和方法,包括数据存储、合并压缩、清洗过滤、格式转换、统计分析、知识发现、可视呈现、关联规则、分类聚类、序列路径、决策支持,等等。[5]
其次来看经济维度。大数据产业是指与数据相关的服务器、存储器、联网设备、软件与服务(按照云计算的观点可将大数据服务业分为数据存储服务、数据软件的开发工具平台服务、数据分析软件平台服务和提供数据分析解决方案的服务),等等。[6]
再次来看政治维度。大数据战略是指政府对大数据的政治认知和政策规划。例如,美国政府将大数据视为“未来的石油”,英国政府则认为大数据可以“开启下一次工业革命”。
最后来看社会维度。大数据思维是指大数据在社会生活各个领域的应用。例如,2009年甲型“H1N1”流感爆发之前,美国谷歌公司利用搜集引擎产生的大数据建立流感预测模型,与随后美国疾控中心通过调查获得的经验数据高度吻合,相关性高达97%。[7]
上述四个维度互为支撑:如果大数据技术无法突破,大数据产业、大数据战略、大数据思维也都无法实现;大数据产业的发展、大数据战略的提出和大数据思维的应用反过来推动大数据技术的开发;如果没有大数据技术、大数据产业和大数据战略作为支撑,大数据思维在社会生活各个领域的应用就会非常有限。见图2所示:
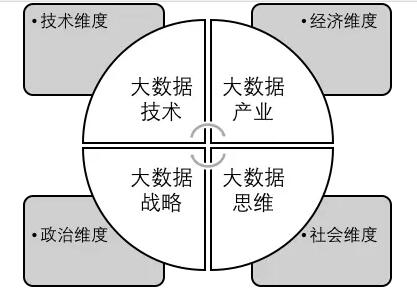
图2“大数据”的维度
大数据驱动的社会治理强调大数据的社会属性,其核心是大数据思维在社会治理中的应用。这至少可以追溯至2001年英国“疯牛病”事件,网民在社交媒体上生成、共享和利用信息。[8]因此,大数据驱动的社会治理也是典型的“先实后名”。在“大数据”的“名”提出之后,大数据驱动社会治理的“实”要有实质性发展,这不仅有赖于大数据思维的形成,也依托于大数据技术的突破、大数据产业的发展和大数据战略的确立。它们共同构成了大数据驱动社会治理的系统要素。
二、大数据驱动的社会治理的学理逻辑
大数据的本质是信息。[9]大数据驱动的核心在于信息驱动。因此,大数据可以通过信息驱动解决中国社会治理的一些难点问题。那么,中国社会治理的哪些难点问题可以通过大数据思维得到解决或缓解?这就需要回到中国社会治理的情境。
中国的社会治理是中国的治理体系中具有显著中国特征的子体系,是对原有社会管理体系的扩展。无论是“社会治理”,还是“社会管理”,它们都是在政策实践中涌现的概念,其学理性都有待进一步厘清。社会管理从内涵上源起于“单位制”的解体。2003年“信访洪峰”之后,针对社会矛盾多发、频发的现实压力,2004年的十六届四中全会提出了“社会管理”的概念,要求建立“党委领导、政府负责、社会协同、公众参与”的社会管理格局,社会管理开始成为一个优先的政策议题。从内容构成来看,当时的社会管理主要包括两大部分:一是政府管理社会;二是社会自治。[10]十八大之后,“社会管理”的概念逐渐被“社会治理”替代,中央文件对社会治理格局的表述也扩展为“党委领导、政府负责、社会协同、公众参与、法治保障”。从内容构成来看,社会治理既包括政府对社会的管理,也包括政府对社会提供的服务,还包括社会的自治。
2011年,胡锦涛在省部级领导干部提升执政能力培训班开班典礼的讲话中界定了中国社会管理的七大任务:协调社会关系;规范社会行为;解决社会问题;化解社会矛盾;促进社会公正;应对社会风险;保持社会稳定。[11]从“社会治理”与“社会管理”这两个概念的演变关系来看,这七项任务也都可以成为中国社会治理的主要任务。从工作领域来看,社会治理可以包括应急管理、社会保障、社会服务、社区自治、社会治安、计划生育、市政公用、教育、住房、医疗、交通,等等,难以完全列举。这是因为,中国社会治理的核心是政府与社会关系,凡是涉及政府与社会关系的领域,都可以划归社会治理。由于中国转型期政府与社会关系的张力,社会治理的主要任务就是化解这种张力,解决社会问题、化解社会矛盾、促进社会公正、应对社会风险、保持社会稳定都是此例。
总体来看,中国的社会治理面临三大难题:一是“数据孤岛”问题。这是一个世界性难题,并非中国独有。“数据孤岛”问题根源于政府体系的科层结构,这是人类社会自进入工业社会以来就开始面临的问题。科层结构的预设在于,复杂任务被分解成小的、相互独立的部分来处理仍然可以实现总体目标;[12]然而,公共问题几乎都是不可分解的,社会治理面向的则都是公共问题,也都不可分解。由此可见,科层结构必然导致“数据孤岛”,社会治理的“数据孤岛”只是这一问题的一个侧面。在社会治理领域,“数据孤岛”造成信息分割,不仅影响政府管理社会的效率,也降低了政府服务社会的质量。例如,由于信息的分割,在2003年“非典”初期,北京市卫生行政主管部门低估了“非典”疫情的严重程度,导致应急响应迟缓、滞后;在2015年“天津爆炸”事件当中,海关和消防之间的信息分割导致了先期响应的决策障碍。
二是“原子化个体”问题。这是中国社会治理的独有问题。“单位制”解体之后,公民成为“原子化的个体”。一方面,中国庞大人口规模使得“原子化个体”在总量上也很庞大,不管是政府管理社会,还是政府服务社会,如何满足规模庞大的“原子化个体”千差万别的需求都是巨大的挑战。另一方面,中国的社会组织长期处于低度发展的状态,“原子化个体”的组织化一直进展不大。
三是社会自治参与不足的问题。在社区层面,社区自治一直面临着参与不足的问题,主要原因则在于:第一,社区居民对公共事务缺乏热情;第二,低效能感,在“大政府、小社会”的格局下,社区自治的功能十分有限;第三,社区居民参与社区自治需要付出时间、精力成本,这与参与的低效能感又形成反差,进一步阻碍了社区居民参与社区自治的热情。社区自治参与不足不仅使得一些原本可以由社区提供的社会服务变得“可望而不可及”,也使得社会服务难以贴近社区居民差异化的需求,导致社会服务的供需错位。这三个因素往往相互影响,互相强化。
上述三个问题并非中国社会治理的全部问题,但却是核心问题。这些问题无法通过“一事一议”的方式予以解决,而必须对社会治理进行系统升级。大数据提供了一个契机,通过大数据驱动的整体性治理、精准化治理和参与式治理可以成为中国社会治理系统升级的努力方向。其中,整体性治理主要强调治理的主体的多元化,大数据可以通过主体之间的数据共享来解决“数据孤岛”的问题,进而促进治理主体的多元化。首先,政府部门之间的数据共享可以通过规范政府数据采集的标准、建设统一的政府大数据中心等方法予以解决。其次,政府、市场、社会三者之间的数据共享可以通过政府开放数据、建立数据交易机制等方法予以解决。精准化治理主要强调利益的多样性,大数据可以通过数据匹配的方式进行人群识别、需求识别和方式识别,使“人民”的政治修辞具体化为不同的利益群体、独特个体,从而实现对数量庞大的“原子化个体”的差异化服务。参与式治理主要强调主体之间的互动性,大数据可以通过数据互动的方式降低社区自治的参与成本,提升社区居民参与社区自治的效能感,培育社区居民的公益精神,促进政府与社会之间的协同。在大数据时代,社区居民通过互联网进行互动的过程本身也是大数据的生成过程。见图3所示:
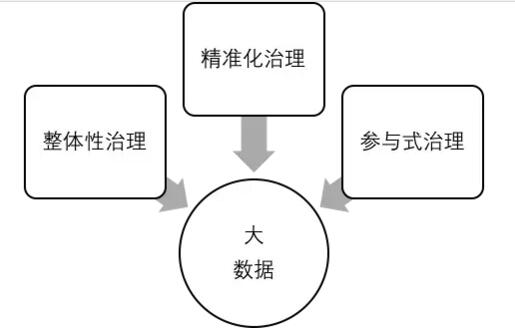
图3大数据驱动社会治理的学理逻辑
实际上,整体性治理、精准化治理、参与式治理都是治理的应有之义。不管治理的概念如何界定,其基本含义都是多元主体之间通过互动实现利益的共享。因此,整体性治理强调的主体的多元化、精准化治理强调的利益的多样性、参与式治理强调的主体之间的互动性原本都在治理概念的内涵之中。从语义学上看,在“治理”之前添加“整体性”“精准化”“参与式”等修饰语旨在进一步凸显治理概念的三个基本要素,以及大数据驱动的三种机制:数据共享;数据匹配;数据互动。与此类似,“社会治理”“企业治理”“国家治理”“全球治理”等这些附加了修饰语的概念原本也都是治理概念的应用之义,只是各自强调的作用领域不同。在这种意义上,整体化治理、精准化治理、参与式治理既相互交叉,又相互促进,难以做出截然的划分。
大数据驱动社会治理的应用领域可以有很多。在整体性治理上,以社会治安综合治理为例,2016年3月1日,中国《社会治安综合治理基础数据规范》(GB/T31000-2015)正式发布,共有26个部委参与标准的制定。[13]这也意味着,只要共同遵守数据规范,这26个部门之间就可以实现数据共享,在较大程度上实现社会治安的整体性治理。以“反恐”为例,2013年“波士顿马拉松爆炸事件”中,通过对现场观众社交媒体的大数据分析,迅速识别了恐怖分子的形体特征。[14]以信访为例,网络信访可以使“数据多跑路,群众少跑腿”,基于网络信访的大数据分析则可以成为社会矛盾的预警提供有效支撑。以食品安全为例,大数据可以实现食品生产、加工、销售全程监控和可追溯。以传染病防治为例,不仅有谷歌公司甲流预测模型的成功先例,政府也可以利用药店监测数据预测流感爆发作为辅助手段。
在精准化治理上,“网络约车”就是典型例证,虽然“网络约车”目前在发展过程中受到一些政策约束和利益集团的抵制,但在提供差异化的社会服务上的优势是不可阻挡的。大数据的应用也可以促进“精准扶贫”,在精准识别扶贫对象上具有优势。在中国的互联网公司中,百度、腾讯和阿里巴巴无疑都是大数据的拥有者,这些数据不仅可以用于商用,也可以用于社会治理。例如,百度的搜索数据在反恐上大有用途。“一个人买高压锅很正常,一个人买钟也很正常,一个人甚至买一个火药也正常,买个钢珠也正常,但是一个人合在一起买了那么多东西,就一定不正常了。”[15]
在参与式治理上,“随手公益”、全民“反恐”、全民“反腐”、政务微博、政务微信都是值得期待的实践探索。
三、大数据驱动社会治理的制约因素
大数据驱动的社会治理根植于特定的社会系统,除技术因素外,不可避免地会受到文化、制度和结构等因素的制约。见图4。只有正视并破除这些制约,大数据驱动社会治理才有可能告别“有名无实”,做到“名副其实”。
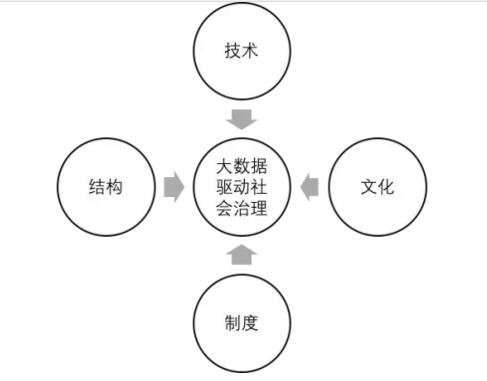
图4大数据驱动社会治理的制约因素
(一)技术约束
技术约束仍然是大数据驱动社会治理的首要障碍。以社交媒体大数据为例进行说明。从数据来源看,社交媒体数据也是大数据的重要来源,尤其是在发生重大灾难事件之后,公众基于社交媒体的参与生成了大量的数据。然而,即便在研究中,目前对灾难情境下社交媒体大数据的使用仍然只是“大样本数据”,而非“大数据”。[16]在社会科学的研究中,通常很难获得全样本数据,而只能基于对总体的粗略估计进行抽样。按照传统的抽样方式,样本规模的经验标准为:小样本(100~300);中样本(300~1000);大样本(1000~3000);在同样的置信度和误差水平下,样本达到一定规模后,即便再增加样本规模,样本对总体的代表性的改善并不大。[17]例如,在1936年的美国总统大选中,《文学文摘》进行的民意调查的样本规模为240万,但预测结果是错误的;盖洛普(GeorgeGallup)创立的美国舆论研究所开展的民意调查样本规模为5000,却能正确预测;导致这一悬殊差异的原因在于数据的代表性。[18]因此,在达到一定的样本规模的情况下,如果数据代表性存在问题,再增加样本量的意义非常有限。这就意味着,“大数据”“大样本数据”并不必然提升研究质量,也并不一定比现有的研究方法更能获得关于社会规律的认识。因此,在大数据环境下,数据代表性仍然非常重要。然而,“大数据”往往因其“大”而忽视数据代表性,数据量大也增加了对数据代表性进行分析的难度。
实际上,在社交媒体上,由于推特(Twitter)、微博等社交平台均对数据获取进行IP限制,导致同样难以获得全样本数据;即便能够获全样本数据,在传统的统计分析之外,现有的分析技术只能提供诸如“词云”(WordCloud)之类的简单分析,意义非常有限。在很多情况下,“大样本”数据加工只能依靠研究者进行手工编码,使得基于社交媒体大数据的研究成为一项“耗费劳力”(laborintensive)的研究工作。[19]
当然,大数据的最大价值并非在大样本或全样本,而在于多源异构数据的涌现性(emergence),即通过数据之间的关联涌现出规律,从而与社会科学研究归纳方法和方法逻辑区别开来。在社会科学研究中,归纳逻辑强调从特殊到一般,最后才形成理论;演绎逻辑强调从一般到特殊,先要有理论假设。多源异构的大数据在形式上类似于演绎逻辑使用的量化数据,在实质上则更接近于归纳逻辑的从现象到理论。然而,归纳逻辑源起于从对物质世界的考察转向对心智的运用,强调研究者主体性,这与多源异构的大数据通过数据的自动涌现来识别规律和提出理论有着本质的不同。正是在这种意义上,大数据分析通常被认为是可以脱离研究者的主体性,不需要理论的指导。然而,目前大数据分析技术最大的障碍恰在于大数据的多源异构性。在已经产生的基于政府数据、物联网数据、互联网数据中,视频等非结构化数据的估算占比为90%,但非结构化数据的挖掘技术离实用还有相当的距离。[20]
(二)文化约束
无论是在中国传统文化中,还是在当前的社会价值导向中,都存在着制约着大数据发展的因素。在中国传统文化中,正如历史学家黄仁宇所言,中国人缺乏“数目字管理”(MathematicallyManagement)的传统,凡事马马虎虎,不求精确。[21]
在当前的社会价值导向中,“安全”成为事实上的优先价值。在风险社会的背景下,社会发展的历史逻辑正在由“我饿”向“我怕”转变;[22]无论是在社会层面,还是在国家层面,对安全的需求都与日俱增。然而,安全从来都不是一个问题,“多安全才算安全”才是一个问题。在大数据驱动社会治理的过程中,大数据既可以促进安全,也可能增加新的安全隐患。因此,任何基于安全的考量都不能绝对化,如果追求安全的成本高于安全的收益,就会得不偿失,导致“因噎废食”。在大数据发展的过程中,“电信诈骗”等各种利用大数据侵犯个体隐私权、财产权的事件多有发生,但不能因此而限制互联网移动支付的发展;“网络约车”也可能会出现人身和财产侵权事件,但不能因此而延缓网络约车的发展;政府开放数据也可能会出现数据被不法分子利用的情况,但不能因此而放弃政府开放数据。总而言之,大数据本身的安全问题容易成为阻碍大数据发展因素,大数据驱动的社会治理应对此有所警觉。在这一点上,安全研究(securitystudy)的开创者、美国学者沃尔弗斯(Arnold Wolfers)指出,“安全”是一个含混不清的概念,容易成为制造战争、悬置民权和资源分配的借口。[23]从本质上看,大数据隐藏的安全风险正是贝克(Ulrich Beck)所说的“现代性的自反性”(reflexivityof modernity),是现代科技与制度的“负面后果”(side-effects),在根源上就是无法避免的。[24]对于这种新兴风险(emerging risk)的监管,不能动辄以“安全”的名义予以严格规制,而应该给予创新的空间。
当然,大数据的确可能带来数据监控(dadasurveillance)造成的权力异化,但这不是大数据本身的问题,而是权力的问题。
(三)制度约束
从制度情境来看,目前对大数据驱动社会治理的约束因素主要包括社会主义民主制度的不完善、数据粗疏和数据造假。
大数据的本质是信息,政府开放数据就意味着政府开放信息,其附带的后果就是强化了公众对政府的监督。这就意味着,大数据也具有了民主意涵,也正是在这种意义上出现了“数据民主”的概念。中国当前的社会主义民主尚不完善,在国家与社会关系仍然紧张的情况下,政府与公众之间互信程度较低。一方面,政府可能由于缺乏对公众的信任而降低开放数据的意愿;另一方面,公众也可能由于缺乏对政府的信任而怀疑开放数据的真实性。从以往的经验来看,政务公开尚且遭遇重重阻碍,政府开放数据在中国面临的困难可想而知。从现状来看,对北京、上海、武汉等8个城市的调查显示,政府开放数据无论是在开放数据的更新频率、可机读数据的比例、应用频道的数目上均难以令人满意。[25]
数据粗疏也是主要问题之一。大数据分析基于大数据获取,而大数据获取则进一步有赖于数据的调查、编码和存储。在这方面,中国的制度基础仍然比较薄弱。数据的调查、编码和存储的科学程度并不高,制度体系也不健全。除统计部门外,不少的政府部门虽然也定期收集收据并建有大量台账,但大多未经过科学的设计,存在着重要信息缺失、数据不精确、存储随意、缺乏长期维护等问题,这些都会影响到大数据的获取与利用。
数据造假则是更为严重和普遍的问题。由于长期的“惟GDP”导向,政府的统计数据存在着严重的“失真”。十八大以来,虽然“惟GDP导向”的弱化,但统计数据“失真”的情况仍然存在。可以试想,基于“失真”数据的大数据分析得到的必然是“伪规律”,以此指导社会治理只能是“误国误民”。因此,大数据驱动社会治理还必须下大力气解决数据造假的问题。
(四)结构约束
由于社会结构的分化而造成的“数字鸿沟”(DigitalDivide)也是一个不容忽视的问题;否则,大数据驱动社会治理不但不会缩小社会差距,反而会进一步加剧社会分化,与社会治理的初衷背道而驰。
社会结构的区域和城乡分化是最为显著的结构约束。在东部城市,大数据驱动的社会治理具有相对可靠的物质基础。然而在西部农村,移动互联网的接入率还非常低,智能手机的拥有率也还不高。因此,如果忽视由于区域和城乡结构造成的“数字鸿沟”,大数据驱动的社会治理必然造成区域和城乡社会服务的进一步分化,这与中国社会治理强调的“协调社会关系”“促进社会公正”等目标相互抵牾。
基于同样的原因,收入水平、教育程度、职业类型、年龄结构都是影响大数据驱动社会治理的制约因素,可能导致社会服务进一步的贫富分化、阶层分化和代际分化,这些都是发展大数据驱动的社会治理需要考虑的问题。
注:本文节选自张海波:《大数据与社会治理》,《经济社会体制比较》,2017年第3期
*本文系国家社科基金重点项目“新兴风险与公共安全体系的适应能力研究”(项目批准号13AGL009)和教育部新世纪人才项目“中国公共安全体系当前面临的挑战与未来发展方向研究”(项目批准号NCET-13-0284)阶段性成果。
[1]光明网:《建设全国一体化国家大数据中心》。http://difang.gmw.cn/newspaper/2016-10/11/content_116864547.htm。
[2]中国长安网(中央政法委门户网站):《孟建柱:创造性运用大数据提高政法工作智能化水平》。http://www.chinapeace.gov.cn/2016-10/21/content_11374295.htm。
[3]涂子沛:《大数据:正在到来的数据革命,以及它如何改变政府、商业与我们的生活》,广西师范大学出版社,2012年版。
[4]涂子沛:《大数据:正在到来的数据革命,以及它如何改变政府、商业与我们的生活》,广西师范大学出版社,2012年版。
[5]邬贺铨:《大数据思维》,《科学与社会》,2014年第1期。
[6]邬贺铨:《大数据思维》,《科学与社会》,2014年第1期。
[7] Jeremy Ginsberg, et al.,Detecting Influenza epidemics using search engine query data, Nature,2009:457(7232): 1012-1014. http://www.nature.com/nature/journal/v457/n7232/full/nature07634.html.
[8] Chris Hagar and CarolineHaythornthwaite, "Crisis, Farming & Community", The Journal of Community Informatics,2005, Vol.1, Issue 3, pp.41-52.
[9]维克托·迈尔—舍恩伯格、肯尼斯·库克耶:《大数据时代:生活、工作和思维的大变革》,浙江人民出版社,2013年版。
[10]中国行政管理学会课题组:《加快我国社会管理和公共服务改革的报告》,《中国行政管理》,2005年第2期。.
[11]新华网:《胡锦涛:扎扎实实提高社会管理科学化水平》。http://news.xinhuanet.com/politics/2011-02/19/c_121100198.htm。
[12]Rittel,H.W.J., Webber, M., "Dilemmas in A General Theory of Planning, " Policy Sciences, (4), 1973, pp.155-169.
[13]中国长安网(中央政法委门户网站):《社会治安综合治理基础数据规范》国家标准(GB/T31000-2015)全文。http://www.chinapeace.gov.cn/zixun/2016-01/29/content_11320680_all.htm。
[14]人民网:《孟建柱:推进网上信访,让数据多跑路,群众少跑腿》。http://bj.people.com.cn/n/2015/0529/c233086-25051805.html。
[15]中国长安网(中央政法委门户网站):《孟建柱:创造性运用大数据提高政法工作智能化水平》。http://www.chinapeace.gov.cn/2016-10/21/content_11374295.htm。
[16]邵东珂、吴进进、彭宗超,2015,《应急管理领域的大数据研究:西方研究进展与启示》,《国外社会科学》,第6期。
[17]风笑天:《社会学研究方法》,中国人民大学出版社,2005年版,第52页。
[18]涂子沛:《大数据:正在到来的数据革命,以及它如何改变政府、商业与我们的生活》,广西师范大学出版社,2012年版。
[19] Sutton, J., et al., "A cross-hazard analysis of terse messageretransmission on Twitter", PNAS,2015, Vol.112, No.48, 14793-14798.
[20]邬贺铨:《大数据思维》,《科学与社会》,2014年第1期。
[21]黄仁宇:《我对“资本主义”的认识》,1986年。转引自涂子沛:《大数据:正在到来的数据革命,以及它如何改变政府、商业与我们的生活》,广西师范大学出版社,2012年版。
[22] Ulrich Beck, Risk Society:Towards a New Modernity, London: Sage Publications, 1992, p.44.
[23] Arnold Wolfers, "‘National Security’ as an AmbiguousSymbol", Political Science Quarterly,Vol.67, No.4, 1952, pp.481-502.
[24] Ulrich Beck, Risk Society:Towards a New Modernity, London: Sage Publications, 1992.
[25]郑磊、高峰:《中国政府开放数据平台研究:框架、现状与建议》,《电子政务》,2015年第7期。